Introduction
In early 2017, Sumit Gulwani, Rishabh Singh, and I wrote a survey on Program Synthesis. Its goal was to provide a comprehensive overview of the state of the field at the time and to serve as an introduction for newcomers. While complete at the time, the survey got surprisingly outdated in the mere two years. Nowadays, every time someone asks me for an introduction to program synthesis, I point them to this survey but also add 10-20 other links that have recently pushed state of the art. On one hand, this is great: program synthesis is expanding rapidly (ICLR’18 alone had 14 papers on the subject!). On the other hand, I’m getting tired of compiling and annotating these lists of recent links every time 🙂 Ergo, this post — a high-level overview of the recent ideas and representative papers in program synthesis as of mid-2018.
Before we dive in, a few disclaimers:
- I assume you are familiar with program synthesis. If not, you’re welcome to check out the survey in question or this excellent blogpost by James Bornholt.
- As expected, it’s impossible to cover everything, although I tried my best. We never set this goal even for the original survey – there’s an enormous body of great work out there. That said, if you notice some glaring omission, please let me know in the comments, and I’ll be happy to include it!
- The list is skewed toward ML/AI rather than PL. This isn’t because of any personal biases of mine, but simply because the volume of synthesis-related papers in NIPS/ICLR/ACL/ICML over the last couple of years started exceeding PLDI/POPL/OOPSLA. Many prominent researchers now publish in both communities.
- As with the original survey, I tried to organize the post to highlight high-level ideas rather than individual papers. An idea appears in more than one research paper. I also listed notable individual papers in their own section.
- Unlike the original survey, this post focuses only on the ideas and techniques, and not on, say, new applications. There’s also a small section on datasets in the end.
- There’s a fair number of Microsoft Research papers in this list, although I tried my best to maintain diversity.
Neural-guided search
Many program synthesis applications are built on a top-down enumerative search as a means to construct the desired program. The search can be purely enumerative (with some optimizations or heuristics), deductively guided, or constraint-guided. A common theme of many research papers of 2018 has been to augment this search with a learned guiding function. Its role is to predict, for each branch at each step of the search process, how likely it is to yield a desired program, after which the search can focus only on the likely branches. The guiding function is usually a neural network or some other probabilistic model. The overall setup can be framed slightly differently depending on the interaction of components in the search process, but the key idea of combining a top-down search procedure with a trained model guiding it remains the same.
DeepCoder pioneered such combination of symbolic and statistical techniques in early 2017. That system learns a model that, given a task specification (input-output examples in the original work), predicts a distribution over the operators that may appear in the desired program. This distribution can be then used as a guiding function in any enumerative search.1
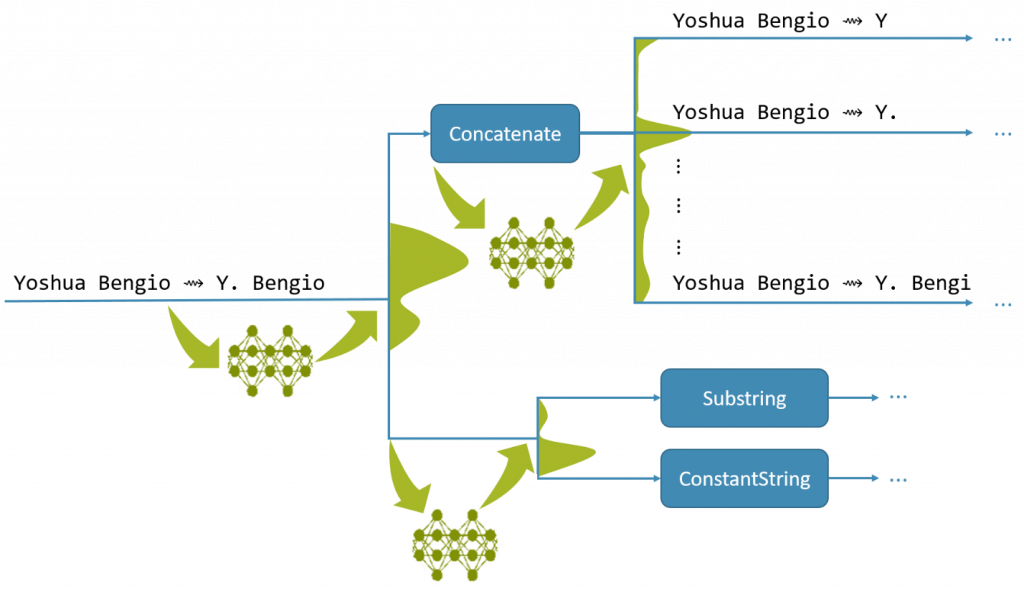
A fragment of the deductive search process looking for the most generalizable program that satisfies the given input-output example. At each branching point in the search tree, the current state is fed into a neural model, which estimates the quality of the best program that is likely to be produced from each branch (shown as a green distribution curve; higher shapes correspond to more promising branches). Source: NGDS.
The subsequent research in 2017-18 pushed this idea further, allowing the guidance to happen at every step of the search process instead of just its root. The guidance can now take into account a partial search state instead of just a global task specification. As expected, this greatly improves the synthesis speed (thanks to trimming down the combinatorial explosion of branches) and accuracy (thanks to the exploration of more promising branches). The key take-away: if you can obtain enough data to train a reliable guiding function, there’s no reason not to do it, it’ll definitely help the search. The main caveat here is that invoking a neural network has a non-zero cost, and sometimes (especially nearing the leaves of the search tree) this can be more expensive than ignoring its prediction and exploring the entire subtree anyway. Also, if the prediction is wrong, there must be a way to detect this, backtrack, and pick a better branch. Thus, careful engineering and something like A*, branch-and-bound, or beam search must be a part of the solution.
- Woosuk Lee, Kihong Heo, Rajeev Alur, Mayur Naik
- Lisa Zhang, Gregory Rosenblatt, Ethan Fetaya, Renjie Liao, William Byrd, Raquel Urtasun, Richard Zemel
- Ashwin Kalyan, Abhishek Mohta, Alex Polozov, Dhruv Batra, Prateek Jain, Sumit Gulwani
- Illia Polosukhin, Alexander Skidanov
- Yu Feng, Ruben Martins, Osbert Bastani, Isil Dillig
Sketch generation
Human programmers often write a program top-down, first producing a high-level description of the desired program structure, and then concretizing the missing details. In other words, we often first produce a sketch of a program instead of writing the entire program end-to-end. In program synthesis, manually sketching the desired program has long been a technique of choice for many challenging domains. However, what if we allow a model to learn the right sketch?
The idea of sketch generation is to split the program synthesis process (Spec $\to$ Program) into two phases (Spec $\to$ Sketch $\to$ Program). The first phase (sketch generation) is usually automatically learned; the second one (program generation) can either be a different learned model or some kind of search. In either case, in order to train the corresponding model, one defines (a) a language of sketches, (b) an abstraction function that produces a sketch of a given code snippet, and (c) a dataset of sketches (usually automatically rewritten from a dataset of concrete programs) associated with the corresponding task specs.
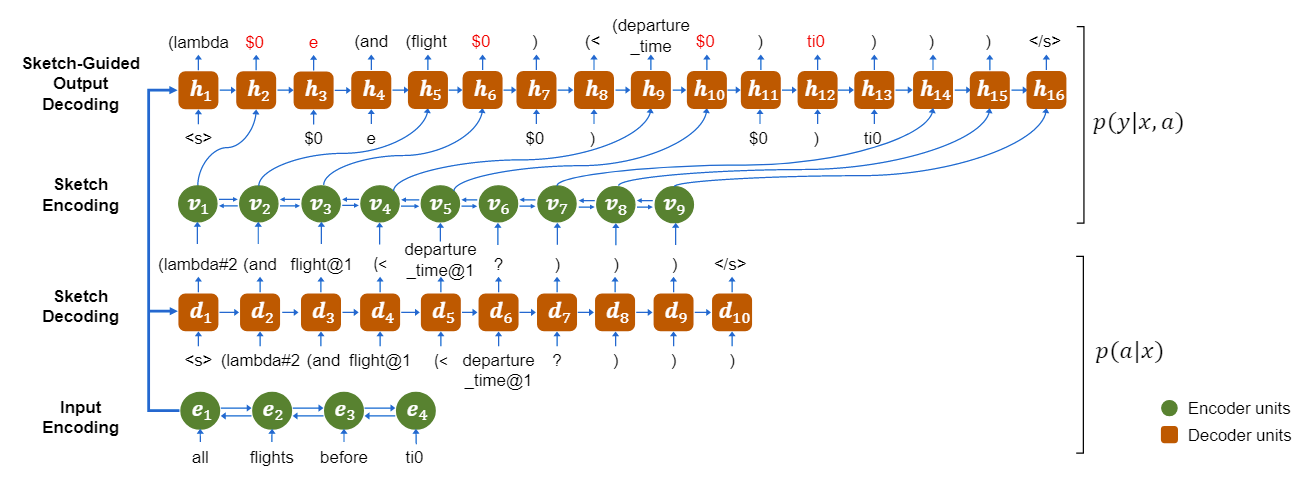
A two-step program generation process, with separate decoder models for (1) a sketch conditioned on the spec and (2) a program conditioned on the sketch and the spec. Source: Coarse2Fine.
Sketch generation outperforms end-to-end program generation. Intuitively, it is easier for a model to learn high-level patterns of the desired program structure rather than its fine implementation details. Moreover, filling in implementation details in a given sketch is much easier than coming up with them on the fly as part of whole program generation. Thus, non-surprisingly, the technique works pretty well on two very different application domains and specification kinds.
Sketch generation was developed independently in Bayou and Coarse2Fine.
Bayou takes as input syntactic specs about elements of the desired program (e.g. “must include a call to readLines and an Iterator type”), and produces the most typical Java program that includes these elements.
Coarse2Fine takes as input a natural language spec, and produces a snippet that implements it (evaluated on Python and SQL snippets from the Geo, ATIS, Django, and WikiSQL semantic parsing datasets).
- Li Dong, Mirella Lapata
- Vijayaraghavan Murali, Letao Qi, Swarat Chaudhuri, Chris Jermaine
Graph neural networks
Graph Neural Networks, or GNNs, arose recently as a particularly useful architecture for tasks that involve reasoning over source code, including program analysis and program synthesis.
The motivation here is the need to treat a program as an executable object.
Most of the ML applications to code before 2017 treated programs either as a sequence of tokens or, at best, a syntax tree.
This captures natural language-like properties of code, i.e. the patterns that arise in programs thanks to their intent to communicate meaning to other programmers.
However, code also has a second meaning – it is a formal executable structure, which communicates a particular behavior to the computer.
In other words, NLP-inspired methods, when applied to code, have to infer the semantics of for, if, API chaining patterns, and so on.
One would hope that this is learnable by a deep neural network from the ground up, but in practice, it’s been exceedingly difficult.
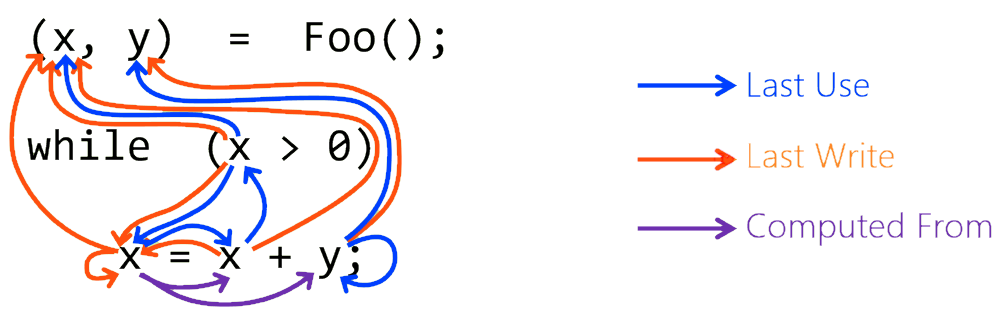
A portion of the data flow graph for a given code snippet, represented with three kinds of auxiliary data flow edges that describe how the variables in the snippet are read and written when the program gets executed. Syntactic AST edges are omitted for clarity. Source: IntelliCode.
A simple way to communicate such information about program semantics to a network is to encode the program’s data flow graph.
It enriches the AST with additional edges that describe how the information might flow in a typical program execution.
For instance, if a variable x is read somewhere in the program, we can connect it with all possible locations where x could have been last written.
The beauty of the method is that it doesn’t care about the semantics of these additional edges, as long as they can be deterministically computed and added to the graph.
For practical tasks (like detecting when a variable may be used incorrectly) the program is augmented with about 10 kinds of such semantic edges.
This augmented graph is then fed into a GNN encoder, which learns the representations for program variables and locations that might be useful for a downstream task, such as variable misuse detection. This is the approach that worked best for a number of software engineering tasks.
What does it have to do with synthesis? Well, once we’ve established GNNs as a good architecture for processing programs,2 then it’s only natural to apply them for program synthesis as well. Recently, we’ve tried to do just that. The idea is to frame program synthesis as a top-down generative model where at each step you (a) decide a grammar production to expand the next “hole” in your partial program, (b) use GNN propagation to update the representations for the relevant nodes of the partial program, (c) refocus and repeat once the entire program is complete. The whole process can be conditioned on any specification, but in our initial experiments we’ve focused on the hardest possible setup – infer a missing program subexpression just from its context, i.e. from surrounding source code alone. That’s hard. Especially on “real-life” source code (we applied it to various C# subexpressions from popular GitHub projects). We’ve reached 50% top-1 accuracy, which for this kind of setup, I think, is already pretty remarkable.
- Miltiadis Allamanis, Marc Brockschmidt, Mahmoud Khademi
- Marc Brockschmidt, Miltiadis Allamanis, Alexander L. Gaunt, Alex Polozov
Datasets
The recent transition of program synthesis into an AI discipline had another nice side-effect — a flurry of new datasets. Neural networks are data-hungry, so researchers are forced to find problems with tens of thousands of data samples, or invent new problems where such a dataset can be creatively generated/collected, and pose a challenge for the field. Sometimes even collecting this dataset can be a genuine ML problem in itself.
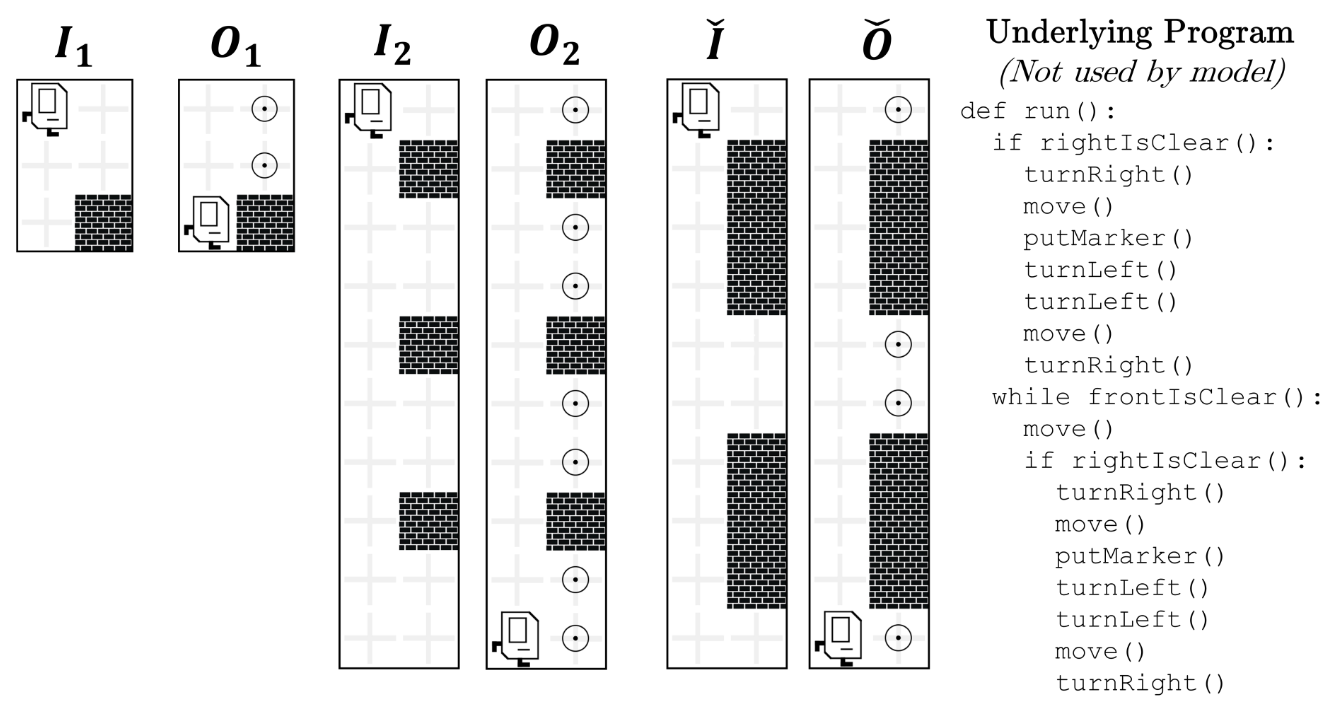
A typical problem from the Karel dataset. The system is given two input-output examples $I_1 \to O_1$, $I_2 \to O_2$, and it has to synthesize a program that also passes a held-out test example $\check{I} \to \check{O}$. Every example is a grid environment for the robot, with walls and markers (potentially of different sizes). Source: Neural Program Meta-Induction.
Here are some datasets that the community has lately focused on:
- Two new semantic parsing (English $\to$ Python) datasets, collected from StackOverflow: StaQC and CoNaLa.
- Karel, a toy robot programming language that used be to used for introductory programming classes at Stanford. The dataset contains synthetically generated programs, each with 5 input-output examples.
- NAPS, a really young and quite challenging dataset containing preprocessed problems from algorithmic competitions along with imperative descriptions and examples.
- WikiSQL, a large semantic parsing dataset (English $\to$ limited SQL). It’s a bit controversial due to its lack of program variety and semi-artificial language generation, but its size and variety of tables/questions has generated a lot of attention after Salesforce released it a year ago.
- A standardized collection of 10 semantic parsing datasets from NLP and DB communities, preprocessed into SQL instead of various logical forms.
Notable mentions
- Jacob Devlin, Jonathan Uesato, Surya Bhupatiraju, Rishabh Singh, Abdel-rahman Mohamed, Pushmeet Kohli
An end-to-end differentiable version of FlashFill that’s trained on a large volume of synthetically generated tasks and can adapt to small noise in the input-output examples. The core architecture is surprisingly simple, but works well for its DSL. Demonstrates an unreasonable effectiveness of attention 🙂
- Yu Feng, Ruben Martins, Osbert Bastani, Isil Dillig
In addition to a variant of statistical branch prioritization, this paper introduces the notion of conflict-driven search from SAT/SMT solving to the program synthesis world.
Loosely speaking, in modern SAT/SMT search algorithms, when a search branch results in a failure, we can learn a reason for this failure – a new conflict clause (i.e., a particular contradiction) that can be added to the working set of constraints to avoid a similar mistake in the future.
In contrast, search algorithms in program synthesis couldn’t do that — until now.
Now, for instance, an input-output example $[1, 2, 3] \to [2, 4]$ not only immediately eliminates any program of form x => map(x, ...) (because map can’t change the length of its input list), but also generates a constraint that eliminates x => reverse(x, ...) and x => sort(x, ...) for the same reason.
- Kevin Ellis, Daniel Ritchie, Armando Solar-Lezama, Joshua B. Tenenbaum
A neat paper that introduces a novel program synthesis problem (recovering $\mathrm{\LaTeX}$ programs from hand-drawn mock-ups) that nicely combines perceptual and symbolic techniques. There are many technical challenges: dealing with noise in the input, recovering the right primitives, optimizing the resulting constraint problem with a learned policy, and so on.
- Abhinav Verma, Vijayaraghavan Murali, Rishabh Singh, Pushmeet Kohli, Swarat Chaudhuri
Have you ever wanted to understand the behavior of your learned RL policy? Or maybe not 100% understand, but at least get some insight into its logic, or maybe replace its logic with something more interpretable and generalizable. Turns out, program synthesis can help. The method is straightforward and beautiful in its simplicity: train a policy to, say, drive a race car, and then search for a program in an appropriate DSL to approximate the behavior of this policy. (The devil, of course, is in the details: DSL design, good sketches, and a method to intelligently sample examples from the policy are all key to making this work.) The program is not as perfectly optimized for the fastest track completion as a neural policy, but it drives smoother, provably generalizes to other tracks, and, most importantly, you can read it. All these benefits become apparent in a video.
- With sincere apologies to Yoshua Bengio, who hasn’t been asked for consent to using his name in the illustrations. We all know how hard it is to make new figures, so the choices you make in a preprint often live on in posters, talks, and blog posts. 🙂 ↩
- I’ve heard people say that GNNs are to programs are what CNNs are to images and LSTMs are to text — if not necessarily a silver bullet, then at least a baseline architecture of choice. I personally think it’s not as clear-cut yet, but explicit reasoning over graphs and relations should definitely be involved in most AI tasks out there. ↩