Next week, I am excited to join Reflection AI as a Member of Technical Staff to help build the frontier open intelligence ecosystem of the Western world.
Spending the last few years at Google (X → Labs → DeepMind) during the founding years of the AI revolution was an opportunity of a lifetime. Working on Gemini and Jules with some of the smartest and most ambitious (and fun!) people on Earth – even more so. I will miss them fondly. But as 2025 unfolded, I found myself reflecting on the state of the AI ecosystem in the U.S. and on my work’s impact on empowering software builders… something critical was missing. This post is my attempt to articulate what.
NOTE: This is also my first blog post in… 7 years, apparently? Most of the older ones were from grad school 😅 Hope that changes – I remember enjoying blogging and tweeting about my work, which got somewhat disrupted by the whole “highly-confidential-frontier-lab” thing.
AI as a platform technology
I started my career in programming languages and developer tools. The devtools culture should be an inspiration to all technologists – they focus less on building a product and more on building a platform that enables millions of builders to create new products. What constitutes a “platform” varies – Microsoft popularized the desktop OS and SDKs; Amazon popularized cloud computing; Apple popularized mobile apps. We are now in the next, and possibly last, cycle of platform technology – AI enables all kinds of individuals, tiny teams, or companies to create applications previously thought impossible. It seems to be growing faster than any technology in modern history, with Gemini alone processing 1.3 quadrillion monthly tokens.
But this platform is different – as a builder, you don’t control or fully understand it. Sure, you might not control the binaries of Windows OS or machines in the AWS data center either – but you understand the behavior of the components you use. OS APIs are documented and usually deterministic; the VM specs are well-known and can be re-provisioned at will. Not so for an LLM API. You make a black-box call into a model with limited customization (context engineering, sampling parameters, tool definitions, multiturn agent logic) and iterate for a consistently satisfactory result. Often it is. Sometimes not.
If I were building the next Bloomberg Terminal with AI insights, or AI-driven customer support at a major airline, or a government-contracted public benefits assistant for an EU country… that level of control and reliability would be unacceptable. Yes, models will improve, but human psychology won’t. For any of the above, I would emphasize finetuning my models and owning as much of the stack as I can – just to derisk. A good platform empowers competent builders to own, tinker with, and build upon its components.
This realization helps us deduce a few things about the medium-term future:
We shall see a growth of AI tuning expertise – engineers post-training their own domain- or skill-specialized LLMs. While today “AI Engineer” denotes LLM-aware application building expertise, the next tech cycle will expand it onto LLM post-training too, once again blurring the line with “ML Engineer”. We can already see that in the blossoming ecosystem of RL environments.
Serious enterprises (e.g., Fortune 500s, hedge funds, sensitive-industry startups, governments) will integrate AI in their applications with more homegrown models, environments, and evals. The art and science of LLM development, currently contained in ~5 frontier labs, will commoditize as a subdiscipline. Specific trade secrets may stay hidden for months or even years – but the methodology will spread as soon as the application builders are ready.
Infrastructure layers of the ecosystem will happily provide for this newfound demand. Jensen Huang is already building 100 of his so-called AI factories – data centers specialized for AI, possibly serving individual industries or companies. Serious enterprises will want their homegrown, user-data-tuned AI to run on-prem or in a leased AI factory. A private cloud with an alphabet soup of compliance acronyms won’t cut it.
NOTE: I am not making any predictions about a hypothetical AGI-assisted world here. The frontier-lab race to develop and own AGI makes a lot of sense, will continue, and, if successful, will change most of the technological tenets of this essay unrecognizably. That won’t be easy to “control”. I reserve any judgements about that world.
But I think the medium-term road there, using “AI as a normal platform technology”, looks clearer.
The coding bellwether
For evidence of this trend, look at coding 🙂 Code AI has always been a bellwether for our industry – largely because researchers and engineers love building tools to accelerate ourselves first, and thus it becomes a frontier indicator of AI innovations. Github Copilot was the first successful LLM product, more than a year before ChatGPT. Cursor and Devin were the first useful agents – reliably completing 10-step tasks months prior to the current wave of travel booking demos.
So what are Cognition (Devin, Windsurf) and Anysphere (Cursor) doing recently? Training models. Just last week, Cognition released SWE-1.5 and Cursor released Composer – domain-specialized agentic models finetuned on in-house traces of real-world SWE tasks. Perhaps more interestingly, Cognition also presented SWE-grep – a specialized LLM finetuned for one component of the agentic system, in this case context retrieval. These are our first signs of model innovation in the agentic app layer, not just software/context/tooling innovation. That will multiply.
Finetuning does not require open weights – all frontier closed-LLM providers have offered tuning APIs for the last ~2 years. However, anecdotally, they have not taken off much:
Iterating on a closed-model finetune is slow, expensive, and can’t unlock the full tinkering abilities of an AI engineer. It does not compare to the experimental velocity of your own H100 or DGX SPARK (measured as ablated insights per week rather than raw hardware throughput).
For the aforementioned control & ownership reasons, closed models are not even in consideration for serious enterprises. They hope to close the frontier gap with customer data instead. As we are starting to see in coding, that’s viable for task- or domain-specialized LLMs.
Now, setting aside the open-vs-closed gap, where are our best open models coming from?
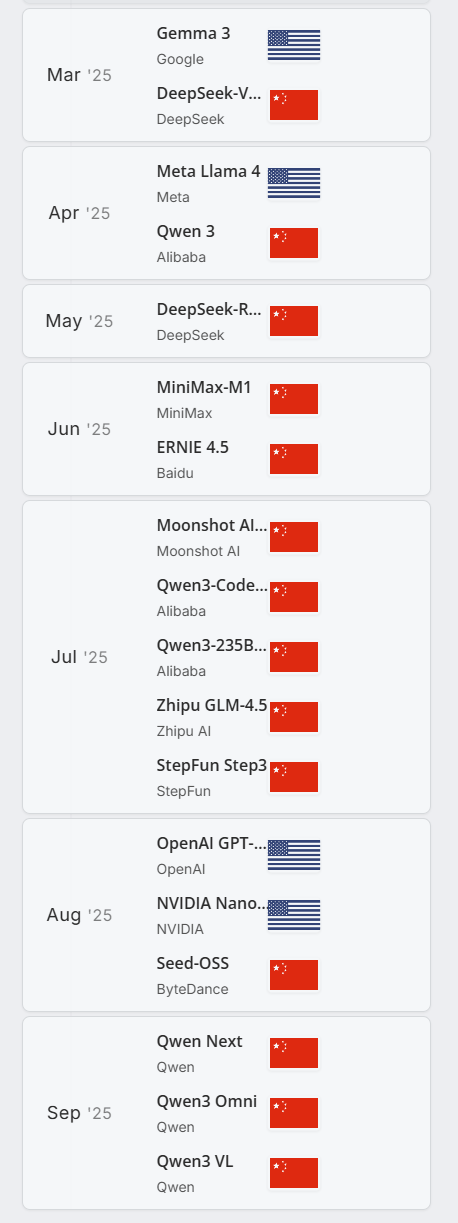
This chart is from The ATOM Project - American Truly Open Models manifesto. As of early November 2025, the past six months saw four American open model releases and 14 Chinese ones.1 The Chinese open models are solid – while not reaching the state-of-the-art closed-model frontier, they are good enough to build upon and ship to real products (as Windsurf and Cursor successfully demonstrated). The Western alternatives… less so.
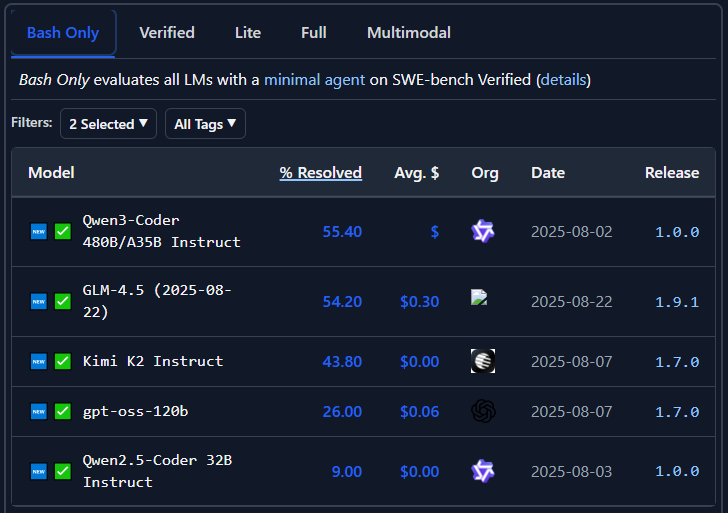
Market adoption is a more important argument that any benchmarks, so HuggingFace Trends and the Windsurf/Cursor deployments should speak for themselves. But if they don’t, look at our favorite marketing datapoint for agents – SWE-bench. Keeping the harness constant (“bash-only” minimal agent) and filtering to open-weight models, we have:
The 29-point gap between Qwen3-Coder and gpt-oss-120b is wild. Especially so as the closed Western models (Claude 4.5 Sonnet and GPT-5) range in 65-70% territory (and surpass 80% with bespoke agent harnesses). We don’t have comparable numbers from Llama 4, Magistral, or Command-A, but nobody I know expects them to match Qwen3 or GLM 4.6.2 Nobody I know is building upon them either.
Does it matter where your open model originates? Even setting aside regulatory and PR risks (which alone are sufficient to discourage most Fortune 500 CTOs, I imagine), a Chinese model is a perilous and inconvenient technical choice for an American application stack:
I prefer reading my model’s reasoning traces in a language I understand;
I prefer to avoid lawsuits about data provenance and copyright choices in my AI features;3
I don’t want to wonder about cultural alignment of my customer-support agent;
And if I do discover a mismatch, realigning it with company-specific post-training is really hard. Even frontier labs notoriously struggle training away behavioral quirks all the time, OpenAI’s sycophancy incident being the most famous recent example. For enterprise AI engineers, I don’t envision alignment as a core competency any time soon, unlike task-oriented post-training.
Put another way, if a Western and an Eastern open model match in performance, any American company should surely pick the former. But we are not even close to such a match.
This disappointing state of affairs is obvious to many, has existential political connotations to some, and thus obviously going to change. By the end of 2026, I expect at least three strong Western open models on the market, Reflection chiefly among them. Will Brown predicts 7+ but that might be overly optimistic. After all, there are reasons for the underperformance of Western open models to date – not for the lack of trying – and it’s hard to predict who will avoid the past mistakes.
Ingredients
Suppose you decided to capture the open-weight frontier. In 2025-2026, for this recipe you shall need:
✔️ Funding for enough compute to supply your staff with experimental velocity. Most of the compute goes to ablations rather than hero runs, so the compute-per-researcher ratio is a more reliable predictor of success than raw FLOPS.
✔️ A continuous partnership with a hyperscaler. It’s not enough to procure your GPUs once, you must be able to expand compute when you hit milestones, cross-license your models for enterprise serving, benefit from SaaS support and GTM, and rely on the partner for subsequent funding rounds. Reflection has the backing of NVIDIA who was the largest investor in their $2B Series B.
✔️ Independent company structure from closed frontier. This is ironic, but there are deep organizational reasons why it’s difficult for the same lab to lead both closed-weight and open-weight frontiers. I will not elaborate on them. To be fair, Gemma was the best model in its weight class with every generation, but those classes now lag substantially behind stronger Chinese models. It remains to be seen how the weight classes evolve.4
✔️ Talent. For a foundation-model company, I would overemphasize pretraining, infrastructure, evals, data, and tool-assisted reasoning – in that order of importance. SFT is reasonably well understood; RL is by now probably the hottest research topic in the open-source AI community. But the topics above require expertise with relatively less attention outside frontier labs. Reflection understand this, already has the right talent, and is hiring more 😉
✔️ Experimental culture. Really, it flows from the right talent and almost religious fervor for the importance of protocol, methodology, ablations, and deep understanding of your evals and vibe checks.
✔️ Customer obsession. LLMs often fall into a trap of “benchmaxxing” – excellent at, say, scientific reasoning but useless for everyday SWE tasks, data wrangling, or automating enterprise workflows. gpt-oss may be the most famous example. A good foundation-model company is not just a research lab – it should follow the Startups 101 of “know your user needs” and build customer relationships early. And if your customers are Fortune 500 enterprises, it helps to live close 🗽
At this time, I only see Thinking Machines, SSI, Reflection, and maybe Poolside with enough
capitalization to fund all the compute, talent, and data acquisitions. Out of these, Thinky and SSI
are uncertain and stealthy in their product goals, so difficult to analyze. Poolside is now pivoting
toward training foundation models – but I’m unsure about some of the ingredients, plus they haven’t mentioned any
commitment to openness to date. Reflection has the partnership with NVIDIA and hits every ingredient
on that list – with of course lots of work remaining. It will not be easy, and we’ll have plenty
of chances to fail. But this is a journey I’m actually excited to begin.
Which brings me to my most important point.
Join us!
You don’t have to already know pretraining, or post-training, or GPU training infrastructure, or data curation, or evals – but of course better if you do 😉 What matters is whether this vision of the beautiful world of independent AI tinkerers, builder empowerment, and open frontier-model science resonates with you. If you’d like to contribute your expertise to help make it happen, please by all means drop me a note, we’d love to chat. Reflection is hiring in NYC, SF, and London.
Thanks to Misha Laskin, Ioannis Antonoglou, and Aakanksha Chowdhery for feedback on the early drafts of this post.
From a brief scan of the SWE-bench Verified leaderboard that does not control for scaffolding, the closest entrants appear to be DevStral Small 2505 evaluated in the OpenHands harness (46.80%) and Nemotron-CORTEXA, which is a complex parallel-compute harness combining different models for different subtasks (68%). GLM-4.6 achieves the same score with a box of scraps minimal harness.
↩
For example – do we know if GLM 4.6, which Cognition allegedly used to post-train their SWE-1.5, properly removed restrictively-licensed code such as GPL from their base model? Their tech report does not discuss it. I wonder how the software companies using Windsurf feel about this.
↩
This is also why I’m skeptical of MAI and Grok capturing the open-weight SOTA. Meta, too, has infamously abandoned openness after its MSL/TBD restructuring.
↩